
ACOs have encountered challenges with aggregating, matching, and deduplicating extensive, disparate patient data required under the eCQM and MIPS CQM quality measure collection types. Patient matching and deduplication are needed to accurately calculate quality metrics from data across multiple practices and EHR instances.
Read on as we unravel the challenges and several methods to overcome these challenges.
.png?width=2000&height=1125&name=y%20(5).png "y (5)")
For ACOs, the patient population eligible for quality reporting consists of the aggregated ACO participant’s all-patient population, including all patients across ACO participant TINs, after patient matching and deduplication. The eligible population used for quality measurement must reflect 100% of the matched, deduplicated population.
To accurately assess performance, each patient needs to be represented once and only once in the final patient panel. Each source of data, however, may represent the same patient through the same or different identifiers.
Diving into the issue
Duplicate records mean that a patient’s data — including different parts of their medical history — is fragmented and not available in 1 place. With reimbursement increasingly tied to a provider’s ability to impact health outcomes, it’s critical for a provider to gain visibility into the patient’s complete and accurate record, including full utilization history. Missing clarity on a patient’s lab tests, for example, can be the difference between achieving a performance bonus and paying a penalty.
When aggregating eCQM and MIPS CQM data from multiple ACO practices, it’s likely some patients will appear in the data of multiple practices. The successful measurement and submission of quality measures require the capability to effectively perform patient matching.
For instance, if ACO practice A conducted a depression screening for a patient and that patient later had an encounter with ACO practice B but wasn’t screened for depression, that patient should still be included in the numerator for the eCQM depression screening measure. However, if aggregation and deduplication fall short, the same patient could be counted as 2 distinct individuals: one meeting the numerator criteria ("met") and another not meeting it ("not met").
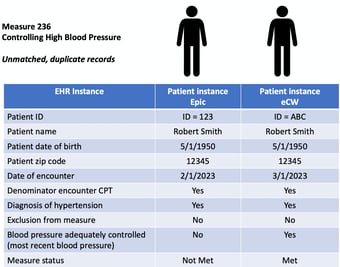
The same is true for the controlling high blood pressure measure. An ACO may have 2 EHRs — an Epic system where the patient id = 123 and an eCW EHR where the patient id = ABC. Patient 123 doesn’t have blood pressure in control in the most recent reading in the Epic system. That patient, however, later has a visit with a different practice using the eCW instance where the blood pressure is in control.
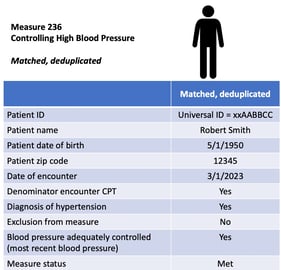
Without patient matching and deduplication, this again could be counted as 2 distinct patients: one meeting the numerator criteria ("met") and another not meeting it ("not met"). By performing patient matching and deduplication, we would see more accurate results, with the patient meeting the measure once.

With practices and EHR instances employing different unique patient identifiers (IDs), patient matching can be daunting. The absence of a universal primary key means we must rely on patient attributes such as name, date of birth, sex, and address to attempt the identification and matching of unique patients.
One practice or EHR, duplicate patients
Duplicate patient records pose a significant challenge. These duplications can stem from a variety of sources, from data-entry errors to the adoption of digital health apps to company mergers and acquisitions. In this list, we explore factors contributing to the proliferation of duplicate patient records and the importance of addressing this issue to maintain data integrity and ensure efficient patient care.
1. Data entry errors. Duplicate health records often originate from data entry mistakes. Medical staff can inadvertently mistype critical information like a patient's name or other identifying details, leading to confusion between 2 distinct individuals. Research conducted among Twin Cities healthcare organizations concluded that a significant number of duplicate patient records occur during the registration process.
2. Digital health apps. Many digital health applications require patients to self-register, which can result in the creation of duplicate records. Patients might provide different contact or identification information compared to what is already on record, resulting in the generation of a new record if the data isn't adequately verified. This issue is prevalent, with 71% of healthcare organizations agreeing or strongly agreeing that portals that allow patients to self-schedule and register contribute to an increase in duplicate record creation and identity-related problems.
3. Mergers and acquisitions. Mergers and acquisitions in the healthcare sector often lead to duplicate records. When healthcare organizations merge or acquire other entities, it becomes necessary to integrate and reconcile patient data from multiple sources to prevent the creation of duplicates. Furthermore, patients may have received care at various facilities within the newly merged or acquired healthcare systems, potentially generating duplicate records if their information isn’t accurately linked and consolidated.
4. Medical technology advances. In an era of rapid medical technology evolution, maintaining data integrity is crucial. Failure to update outdated data can result in the creation of new data entries alongside the old ones, leading to the formation of duplicate records.
5. Incomplete patient records. Incomplete patient records can also contribute to duplicate health records. If a healthcare provider can’t obtain all the required information from a patient, another professional may attempt to re-enter the same data later, inadvertently creating a new record.
6. Lack of standardization. The absence of a consistent format for healthcare professionals to follow when entering information within and across facilities can make it challenging to reconcile and match patient data. This lack of standardized health data management can, in turn, lead to the creation of duplicate medical records and cause confusion.
How can we match?
When we look at patient records from various sources, there are several methods we can employ to patient match and deduplicate:
1. Universal patient ID. If an ACO has set up a universal patient ID across systems, this can be used to aggregate all data from disparate systems and determine a full record of the patient and care. A universal patient ID is the most straightforward way to aggregate data, and some ACOs can use this to move forward.The existence of a universal patient ID would lessen the burdensome matching process and lead to the calculation of more accurate quality measure results. This concept isn’t a new one, and in the past, it has been met with concerns regarding patient privacy.
The issue of ensuring patient privacy should be addressed, and any unique patient ID should be protected like any other form of personal health information. Moreover, it is important to note that a unique healthcare ID wouldn’t link to patient financial information and may enable patients to avoid sharing their Social Security number in certain instances.
2. Demographic data patient matching. Data in each practice and EHR can be matched on key data fields, such as name, date of birth, zip code, and phone number. This can match many matches in uncoordinated data between systems.
Issues still can arise if nicknames are used, data is outdated, or data is missing in some sources. Addresses can be outdated, names might be misspelled, abbreviations may be used, punctation between records can vary, and some health systems may use middle initials while others don’t.
Having said that, this is a viable mechanism to match a significant percentage of duplicates, perform patient matching, and achieve more realistic quality measure calculations. If a universal patient ID isn’t available, the use of demographic data is a practical approach.
3. Referential patient matching. Rather than directly comparing the demographic data from 2 patient records to see if they match, referential patient matching matches that demographic data to a comprehensive and updated reference database of identities. Using a proprietary database such as those used for identity verification and matching in other industries, like banking and credit, identities spanning the entire U.S. population can be used.
Each identity contains a more complete profile of demographic data spanning historical as well as current data. Some call it a pre-built answer key for all patient demographic data. By matching records to this database instead of to each other, referential patient matching can make matches that demographic patient matching technologies may not find.
In summary
Patient matching and deduplication are a challenge. Steps forward can include:
- Identify all the data sources.
- Determine patient ID strategies that have been used in these data sources.
- Has effort been made to use a single patient ID?
- How clean are patient IDs within and across data sources?
- Determine formats and overlaps of patient IDs in data sources.
- Determine the approach to patient matching and deduplication.
- Install appropriate patient matching and deduplication processes.
- Beta test matching and assess results.
- Implement and monitor patient matching.
There are advantages to getting a jump on this process. As we’ve implemented patient matching and deduplication with ACOs and other organizations, we can see a more comprehensive overview of patient care and outcomes. In addition, we’ve seen improvements in performance and the ability to close gaps in care more easily.
Click here to schedule a APP Impact demo/consultation